
Navigating Retrieval Augmented Generation (RAG) Challenges and Opportunities
Insights for AI Founders

Summary - Takeaways
Retrieval Augmented Generation (RAG) will play a key role in the AI stack. Most future RAG users have not yet set up basic, native RAG systems. I expect adoption to increase exponentially in the coming years.
Fine-tuning and RAG are not mutually exclusive. In the coming years, most companies embedding AI in their products or workflows will employ both in parallel. At the current state, fine-tuning is great for things like output formatting/style, and RAG is great for facts.
Most everyone is misunderstanding RAG systems, mistakenly swayed by the apparent ease of launching a basic configuration. This ease of initial setup often masks the nuanced complexities and critical trade-offs required for developing a robust, scalable RAG architecture. It's imperative for founders using RAG to be keenly aware of these trade-offs. They should concentrate on discerning and aligning their primary goals — whether that's efficiency, accuracy, cost-effectiveness, or speed — with their RAG system design, to ensure it's specifically suited to their customer’s needs.
There is a significant opportunity for infrastructure players to build an effective orchestration layer that automatically and dynamically optimizes the various components of the RAG system for specific use cases. This approach will lead companies to have multiple RAG systems running in parallel, each tailored to different products and workflows.
Founders should remember that RAG is a tool, not the entire product nor the only source of differentiation. Focusing on industry-specific needs allows them to concentrate on workflows, which creates higher defensibility and turns nice-to-have solutions into must-haves.
We are still in the early days of RAG systems. Areas like multimodal RAG and efficient scaling are topics of ongoing research and early application that show great promise.
Importance of RAG in the AI stack
Large Language Models possess a parametric memory, which is the knowledge built into the model during its training. This architecture has several implications for companies. On the one hand, it does not incorporate companies' private data into their knowledge unless it was pre-trained on it; on the other hand, it does not have access to the most up-to-date information. Given these limitations, one of the most discussed topics in the AI world last year was Retrieval-Augmented Generation (RAG). RAG is a technique for enhancing the accuracy and reliability of generative AI models with knowledge from external sources. The term was formally coined in a 2020 paper led by Patrick Lewis [Lewis et al., 2020]. (You can read more about the history here; the concept goes back to the question-answering systems in the 70s). The RAG architecture, in a simplified manner, consists of the following five steps:
Input: The process begins with a user query or input, which initiates the RAG system's operation. This query specifies the information or question that needs to be addressed.
Indexing: In this step, data from external databases is organized and indexed. This preparation involves converting various data formats into a standardized form and segmenting the text into manageable chunks. These chunks are then transformed into vector representations, enabling efficient retrieval later.
Retrieval: Upon receiving the user's input, the RAG system uses its retrieval mechanism to fetch relevant information from the external database. It calculates the similarity between the query and the indexed data, retrieving the most relevant documents or data chunks. Although this is the common method of retrieval today, there is room for improvement, and there may not always be a need for vector search.
Generation and augmentation: The retrieved data and the user query are processed by a LLM, which generates a response by synthesizing the input with a blend of its internal knowledge and the external data. This step ensures that the response is not only contextually relevant but also aligned with the LLM's capabilities, enhancing the quality and accuracy of the content produced.
Answer: The final step is the output of the answer or response generated by the RAG system. This answer is expected to be more accurate, up-to-date, and contextually rich, addressing the user's initial query more effectively than a generic LLM query.
Below is a diagram of how a RAG system works. For a comprehensive understanding of RAG system components, Aman Chadha put out an amazing guide (also sharing some additional useful links: 1,2,3).
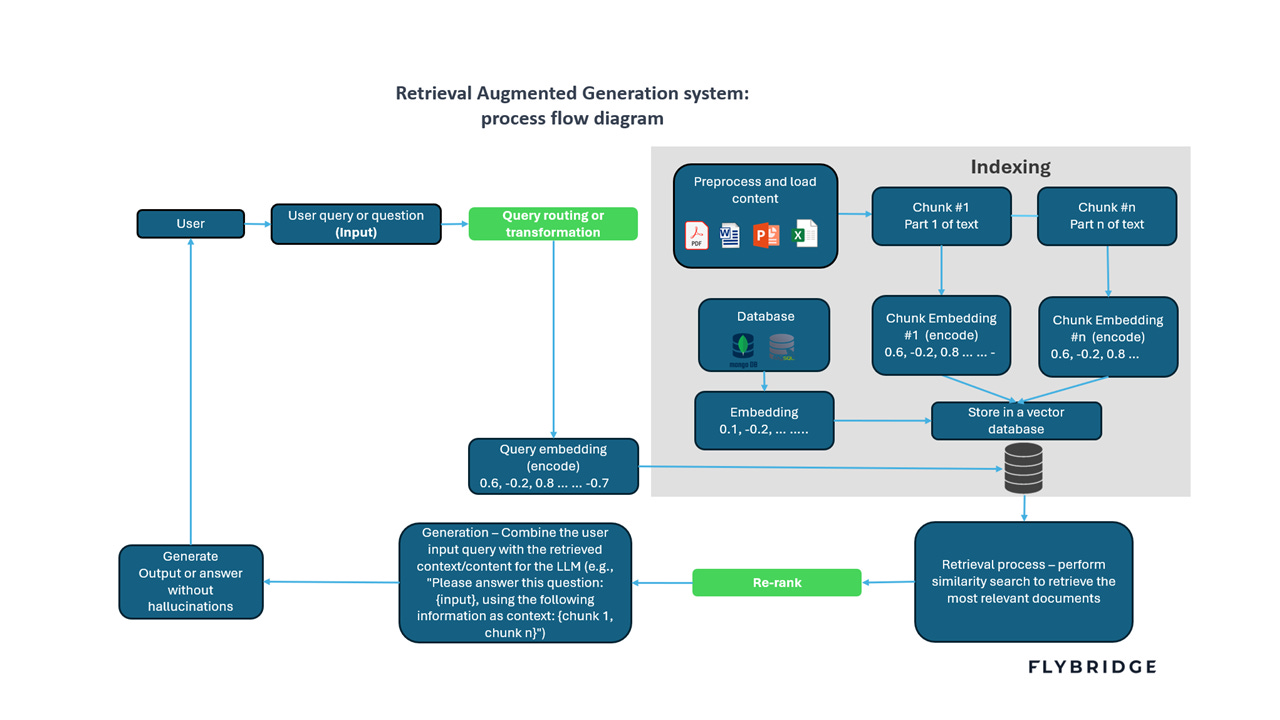
RAG has been widely adopted because it delivers clear benefits: it reduces hallucinations and improves the quality of responses by feeding factual external information when needed. It helps the model access the most recent (and often proprietary) information without needing to constantly re-train the model, which is prohibitively expensive with current techniques. Additionally, it allows for more interpretability or transparency, as a response can be traced back to a specific content source and can even include quotes and citations. Moreover, a significant reason for its increased popularity over other techniques is its ease of implementation. Unlike fine-tuning or pre-training, implementing a basic, naive RAG system does not require labeled data, and the process requires less technical knowledge.
Often, RAG and fine-tuning are viewed as mutually exclusive solutions. However, even when a company needs to fine-tune a model for a specific purpose, such as adjusting the writing style (refer to Appendix A for a comprehensive table comparing fine-tuning and RAG), RAG can still play a pivotal and complementary role in a company’s AI stack. I anticipate that in the future, most companies using AI will incorporate a combination of fine-tuned models and RAG architectures in their stack. For instance, RAG is an essential component for companies that need to connect to real-time data sources and have up-to-date information, as constantly retraining the model is prohibitively expensive and complex. On the other end, fine-tuning embedding models can help improve the accuracy of the retrieval step of RAG, showing how complementary both can be. Pre-training also can have an important role. You may want to pre-train your model to ensure you have the highest quality output and fastest inference for key things even if the process is more expensive and hard, but then use RAG to easily update the data, understanding it will have lower quality and higher latency.
As previously mentioned, setting up a basic naive RAG system is not complicated. You can clone GitHub repositories (Basic, web RAG chatbot), or follow online tutorials. I highly recommend the YouTube channels of Greg Kamradt and James Briggs, who constantly share different techniques and uses of frameworks to build RAG systems. You can get a system working in a couple of hours or less. However, despite how simple it can be to set up, in a recent langchain webinar, Anton Troynikov founder of the vector database company Chroma, mentioned that he believes the majority of future RAG users have not yet adopted basic RAG systems and that they still will not for the next few months. Adopting RAG systems can generate massive value for companies and users. For example, Notion recently announced their Q&A product, which allows users to more easily search and ask questions about the information contained in people's Notion. Another example is Flybridge's Partner Jeff Bussgang, a professor at HBS who created ChatLTV, a RAG-augmented co-pilot for his popular LTV class. This just shows how early we are in the adoption curve and the massive potential this can have for companies that adopt it.
Complexities and techniques for setting a good RAG system
The apparent simplicity in establishing a basic RAG system often overshadows the depth and inherent complexities of applying these systems effectively at scale. Some of the considerations that founder’s have to take into account when thinking of adopting RAG as part of the architecture include among other things:
Domain specific retrieval: Depending on how specific the use case is, it may be necessary to fine-tune the retrieval model. For example, in law, a foundational model may have a general understanding of a word, but that word might carry a very specific meaning in a contract.
How to chunk the documents: There are different mechanisms you may want to use to split the chunks. For example, you may leverage different text splitters depending on the document type you are using. Another consideration is the size of the chunk; smaller chunks are more granular and detailed but have higher odds of missing information. Larger chunks may be more comprehensive but may cause the system to have a slower processing time. Players like Unstructured offer some interesting alternative strategies for chunking, such as chunking based on titles and metadata. Llama Index prepared a useful document on evaluating the ideal chunk size.
What embedding model to choose and should you fine tune your embedding model: There are different models that excel at different tasks. More advanced models often require higher computational resources. Depending on the scale of the application, you may need to prioritize efficiency and speed. The leading companies constantly launch new models. Additionally, if you are going to use terminology or particular industry- or company-specific language that the embedding models were not trained on, you may want to fine-tune your own model. You can refer to the MTEB Hugging Face ranking to compare the different embedding models.
Managing Cost and Efficiency Trade-offs: There are novel architectures and processes designed to make the process more accurate; however, they can lead to higher costs and compute requirements, including embedding costs, vector database storage costs, and retrieval speeds, among others.
Managing Cost and Efficiency Trade-offs: There are innovative architectures and processes designed to enhance accuracy, but they may result in higher costs and increased compute requirements. This includes expenses related to embedding, vector database storage, and retrieval speeds, among others. For instance, this week, OpenAI introduced the successor to the Ada-002 embedding model, enabling developers to shorten embeddings to balance performance with operational costs. Additionally, factors such as choosing between batch processing (for efficiency in resource usage and consistency) and real-time embeddings (for low latency) must be considered.
Particular Cases Like Multilanguage: Not all embedding models understand all languages, and even if there is a word with the same meaning in a different language, it may place them far apart in the vector dataspace.
Multi-hop and Complex Reasoning: Address complex queries that require reasoning over multiple documents and facts.
Orchestration of RAG: Understand when it is necessary to retrieve information and when it is not. Also, determine how to use a particular RAG architecture for a specific use case, and choose different ones for others, depending on priorities such as inference, cost, and accuracy.
Dealing with Distracting Information: Including excessive or irrelevant information in the model's context window can negatively impact performance, as distracting information could hinder the system's effectiveness. The impact of a long prompt with the relevant context in the middle, for example, is showcased in a study done by Anthropic. The goal is to reduce the noise ratio.
Evaluating RAG Systems: Given the variety of RAG architectures available and the need to iteratatively improve quality, evaluation metrics and systems are key to understanding the best approach for the company's use case. These feedback systems should evaluate not only the overall system but also each component separately. (Ragas is a great open source framework to do this)
Permission, access and audits: To reply to a user's query, you may need to retrieve external information. However, depending on the use case, you may also have to ensure that the user has access or permission to that information. In relation, you may need to maintain logs in case an audit is required at some point, for internal or external reasons.
Keeping your system up-to-date: as every other week the different players in the space are launching new techniques, methods, and models. Ensuring your system stays up to date with the most recent architecture, while at the same time ensuring it does not break, can be highly time-consuming.
There are numerous issues with creating an efficient RAG system that are currently the subject of ongoing research. The ACL tutorial has compiled comprehensive materials that illuminate the critical considerations for developers implementing RAG systems. These considerations are encapsulated in three fundamental questions: what to retrieve, how to use the retrieved information, and when to retrieve it. (The complete materials and presentation are available at this link.). The graph below was extracted from their presentation and reflects the different papers on novel approaches to different parts of the process.
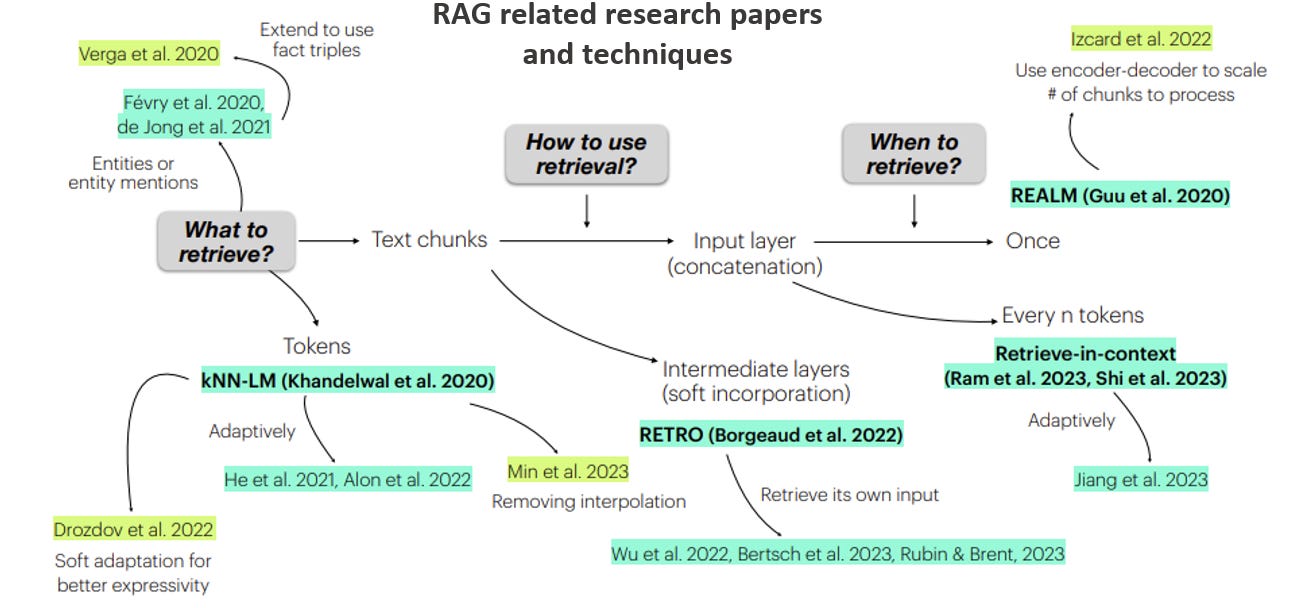
Graph taken from: ACL 2023 Tutorial, Section 3 Retrieval-based LM: Architecture
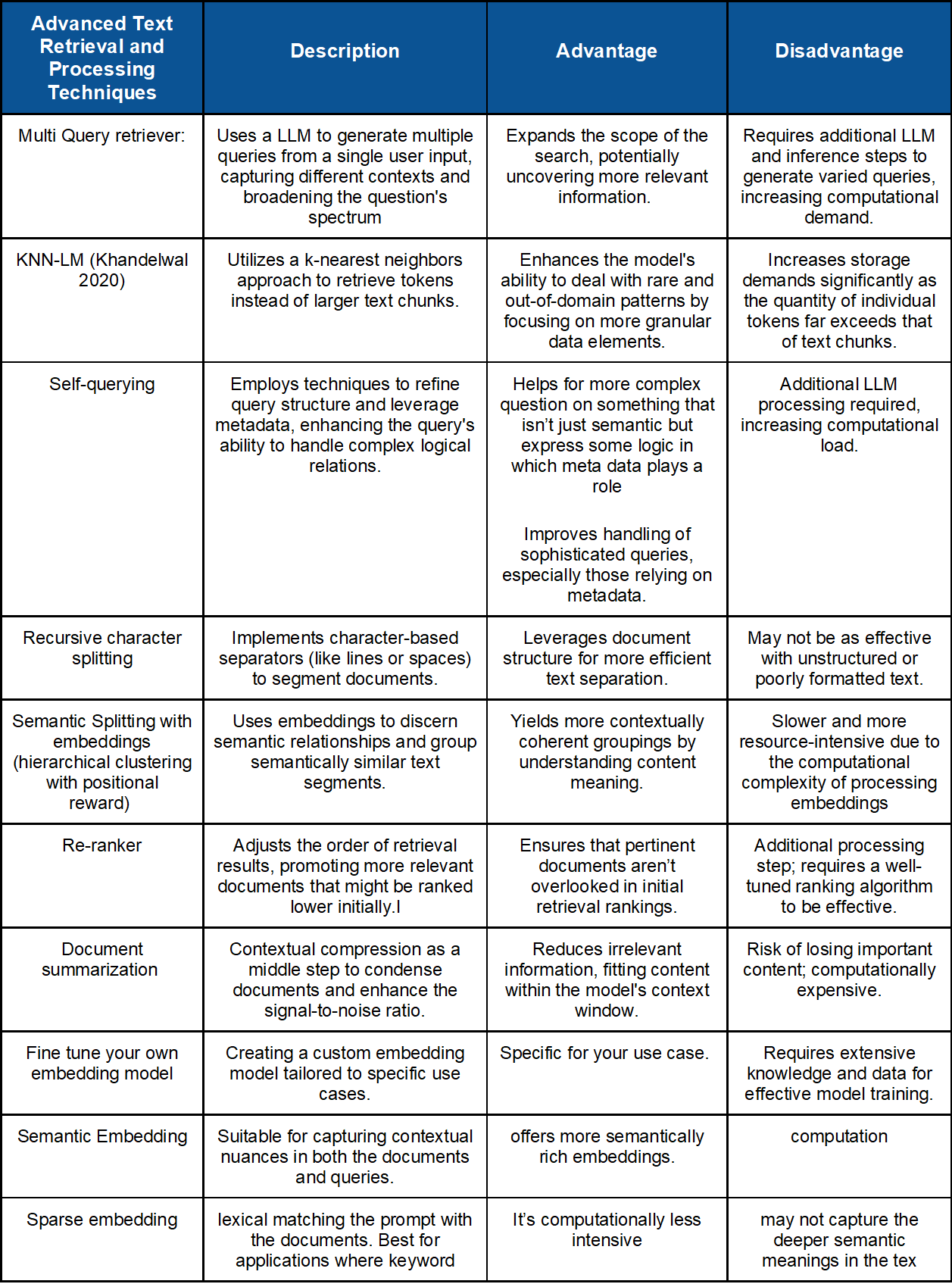
The purpose of this article is not to review each of the papers in detail, as the ACL does a great job going through each one of them (I have made a table to showcase some examples for builders to get an idea of the different techniques and their trade-offs in Appendix B). However, it is to show the amount of depth there can be when deploying a RAG system. For founders, it is especially relevant to understand the task they want to perform and, based on that, define the possible trade-offs involved with taking one approach or another. One thing to note is that a combination of techniques can be applied in conjunction and that there could also be different systems for different use cases within the same company. Another important thing for founders who delve deeper into these techniques is not to deploy them just for the sake of having the latest system, but rather to choose the appropriate system for their needs and client demands. For example, a company that uses a RAG system to offer a service to enterprises may opt to use different techniques to maximize accuracy, like using a multi-query retriever, re-ranking systems, and agentic splitting, to name a few examples.
Main players and approaches in the RAG Space
As showcased above, you can quickly fall into a rabbit hole with the different ways to optimize RAG systems. Although individuals can manage much of this directly, it can quickly become a daunting task. To mitigate many of these complexities, players like LangChain and LlamaIndex have emerged, providing frameworks for successfully deploying more advanced RAG systems. Though they have built great brands and communities and are likely to become some of the biggest winners in the space, I still believe there is opportunity for other players. I think there is a significant opportunity at the orchestration layer for a startup to leverage agents that would self-answer questions of what, when, and how to retrieve information depending on the use case, thereby optimizing the process. Currently, there are agents that address one or two of these aspects, but not all, and not dynamically. With the current state of research, creating a truly optimized, dynamic, and automated system may be impossible or may never reach production due to cost and speed implications. However, I am confident that both will decrease in the coming years, and players building with the mindset that this will happen and who are ready to leverage this at the orchestration layer can have massive potential.
Although LangChain makes the process easier to assemble a RAG architecture, it is still not a simple process, as detailed by the article written by Alden do Rosario founder of CustomGPT. Given this, another alternative to avoid the complexities of assembling the various tools needed to create a RAG architecture is to opt for an out-of-the-box, end-to-end RAG solution.. Players like Vectara offer a solution where you can upload your document to their system and start asking questions that require retrieving information in just 5 minutes. Other players also provide end-to-end solutions but focus on specific industries. For example, Metal began as a broader RAG engine for developers but soon realized the difficulty in differentiating itself from existing and upcoming players. Consequently, they shifted their approach to focus specifically on the financial industry. According to Taylor, the founder
“Setting up a basic RAG system is very different from building a production-grade application to support critical business workflows. We’re focused on the latter at Metal, specifically building for deal teams in PE and VC. Our customers need to index various data types – like board presentations or financial statements – and the bar for accuracy is very high. As a result, Metal’s ingestion infrastructure is highly specialized to work with financial documents, giving us higher data quality to support more powerful RAG use cases. This allows us to build features like proactively alerting fund managers when a company deviates from plan, or instantly mining years of data for a single quote from management”
More players will emerge with a similar approach to using RAG as part of their systems but not as the complete solution. Instead, they will likely focus more on workflows and use cases, targeting specific industries vertically. Having tested this internally, we realized that while extracting information is beneficial, integrating it into workflows is what will make many of these systems critical, must-have solutions.
Other relevant players to highlight in this space are the vector databases where the embeddings are stored. These players are the backbone of RAG systems. For example, Qdrant is believed to be the engine that enables Grok to incorporate real-time data from X. Other players like Pinecone, which recently introduced their serverless vector database, are among the founders' favorites due to their scalability and cost efficiency. This area is highly competitive and is unlikely to see many new players emerging, but rather competition and consolidation among the existing players (for a full mapping of the features and players, refer to VDBS). As in other parts of the stack, apart from startups, established players have also started offering solutions for the new architectures. For example, MongoDB, a former Flybridge portfolio company, announced last year their Atlas Vector Search solution. These players have a significant advantage as they have strong reputations and existing enterprise customers to which they can cross-sell their new offerings. Further, as noted by Silicon Angle in a recent review of MongoDB’s Atlas Vector Search, there is a significant advantage to building vector support as part of a broader developer data platform: “What is cool is a unified ecosystem that supports generative artificial intelligence use cases on the same stack and supports traditional online transaction processing and online analytical processing use cases. In other words, it avoids organizations having to maintain separate stacks for structured data and unstructured, for batch and streaming, and for transactional and analytical. It also puts them on the road to a simplified cost-effective data infrastructure that is easy to manage and grow. On top of that, it provides ironclad data security and governance across a hybrid multi cloud deployment footprint.”
Multimodality and the future of RAG
Much of the focus has been on text, but RAG can also be applied to other forms such as images, audio, and video. There is ongoing research in this area, as demonstrated by Yasuna et al. (2023). We are excited by the number of interesting applications this multimodal RAG will enable. For example, Shade, enables the creation of searchable images and videos, potentially saving marketing teams hundreds of hours (demo).
As mentioned, we are still in the early days of RAG systems. I expect that in the next two years, RAG will continue gaining adoption and relevance. I anticipate that half of the companies embedding AI in their products will use a form of RAG in their systems. Although it is true that novel architectures may make the process of retraining models more efficient, I still believe that RAG will play a key role in the AI stack of companies for many years to come. There is some exciting research in areas like feedback loops, hybrid systems, improving context length handling, and scaling laws of RAG systems that will just keep making these systems better, and I expect the infrastructure layer to keep abstracting a lot of the complexities for application startups in the coming years. If you are a founder building in this space or an operator who wants to exchange views, send me a message at daniel@flybridge.com. You can learn more about our AI thesis and history here.
Thank you to Andrew Lee, Suraj Patel, Alden do Rosario, Taylor Lowe, and my partners Chip Hazard and Jeff Bussgang, who reviewed earlier versions of this post and provided valuable input.
Appendix
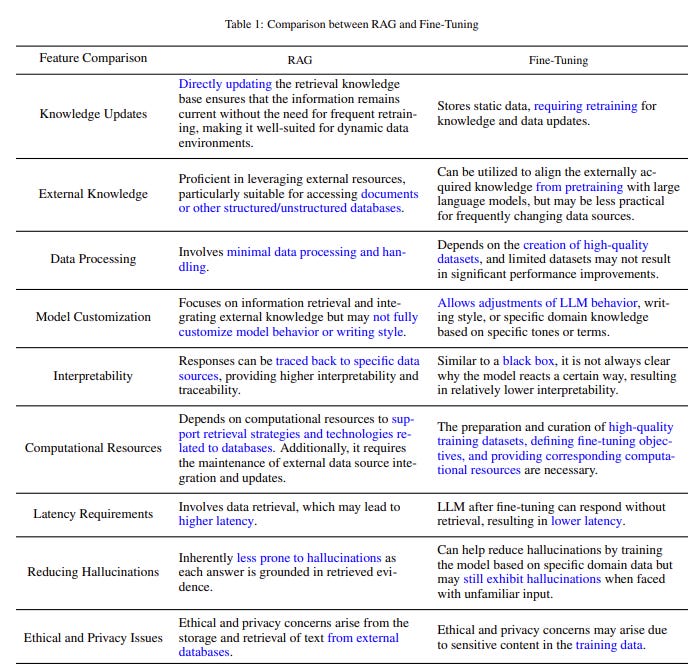
Appendix A: Taken from Gao, Y., Xiong, Y., Gao, X., et al. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. RAG survey paper
Appendix B
The challenges you're describing are exactly what Anthropic hit with Claude Code. Fragile retrieval, inconsistent results, the model not properly understanding context that was handed to it. Their solution? They dropped RAG entirely and let the model search the codebase itself via grep. It built a far better mental map that way. Wrote about their full process here: https://reading.sh/anthropic-revealed-how-they-build-claude-codes-brain-11e48e75fd01?sk=6662727c70ed637cd1692a81f33139e2